The clusterfinder module, TCL, is based in part on an algorithm developed by Mike Levine, Michi Botlo, and David Patterson [2] which has been refined to identify general cluster shapes.
The algorithm is based on building up a list of time-overlapping sequences (see above) by using each sequence in the list as a ``seed'' around which to search for overlapping sequences, which are then added to the list. Any sequence which is added to any list is marked as ``used.''
A schematic of the clustering algorithm is shown in Figure 6. The module identifies and stores clusters of pixels for each padrow by beginning from the ``left-bottom'' (= low pad number, low time bucket number), and searching until it finds an unused sequence, one which has not been associated with a cluster. This sequence becomes the seed. The algorithm looks in succession to the left and to the right of the seed for unused sequences which overlap with the seed. These are added to the list, later to become seeds. When clustering around the seed is finished, the next sequence on the list becomes the seed. When all sequences have been seed, the cluster list is complete, and the seed for a new cluster is the first unused sequence looking again from bottom-left.
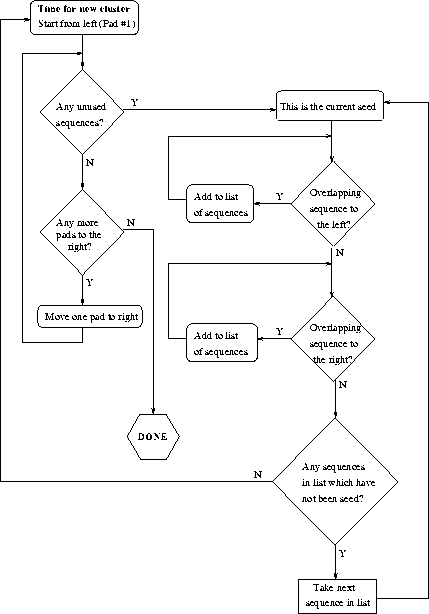
Figure 6: Schematic flow chart for clustering algorithm.
We note that this algorithm finds the most general clusters, as defined above. This includes the three clusters shown in Figure 7. As indicated in the figure, simpler (but faster) algorithms, such as that being proposed for the STAR trigger [2], would break such structures into more than one piece. While there may indeed be reason for breaking such structures into seperate hits, it is the philosophy in the TCL package to perform any hit deconvolution in the hitfinder package, to make the software more modular and maintainable.
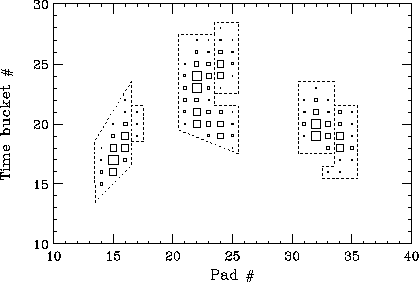
Figure 7: Three clusters that would be identified by the TCL algorithm.
A simpler, more cpu-efficient algorithm breaks the clusters as
indicated by the dotted lines.
The clusterfinder has essentially no tunable parameters. A field in the switch table (see below) specifies the minimum number of sequences for a set of overlapping sequences to be stored as a cluster. The default is 2, simply eliminating noise sequences occurring on individual pads. Reduction to 1 would allow noise into the hitfinding stage, while not increasing the number of good hits. Increasing the switch value to 3 would result in a loss of good two-pad hits.
Currently, sequences in the clusterfinder are defined by the first and last bucket above the threshold set by the front-end electronics (or the slow simulator). One could imagine a second (higher) threshold used by the clusterfinder. The potential utility of such a threshold needs study.